It’s spring of 2023, and if you aren’t paying attention to what’s happening in the world of AI, you really should. The world is about to change in big ways!
I’ll save the general discussion on AI for another post — I’m hoping for this article to be one of a multipart series where we dive into the practical aspects of each major area of advancement. My goal is to give readers a taste of what’s going on, what the capabilities of these AI models are, and why you should care.
Let’s start with image generation models, as they’re the oldest in the recent wave of innovation. Skip ahead to the model comparison and summary section if you are already familiar with text-to-image models!
Text-to-image
The most basic capability of image generation models is to convert a plain language description into a picture. Let’s start there:
“the indian warrior arjuna, riding a golden chariot, pulled by four white horses, in a battlefield, highly detailed, digital art”
This type of text is called a “prompt” in the world of text-to-image models. There are a number of these models commercially available today, and here are a few results from the ones I tried:
 RunwayML
RunwayML
 Dall-E 2
Dall-E 2
 Firefly
Firefly
 Bing (Dall-E 2 Exp)
Bing (Dall-E 2 Exp)
 Stable Diffusion
Stable Diffusion
 Midjourney
Midjourney
Well, isn’t that neat? It’s remarkable that these images have never been created until now. The AI made them on-the-fly based on my prompt, and drawing from its vast knowledge of all images it has “seen”.
A discerning viewer might look at this and not be impressed - you can easily spot a number of defects: the horses aren’t quite lined up right, one of them painted only one horse instead of four, the human faces are pretty blurry and sometimes creepy looking, and so on.
However, I attempted to list the images in order of how impressive they are (yes, I know, art is subjective, bear with me). They come from:
- RunwayML, which seems to be running a very early version of the Stable Diffusion open source generation models (also listed below).
- Dall-E 2, which is a commercial model from OpenAI that kick-started the modern age of image generation models.
- Firefly, the most recent entrant from Adobe that focuses on commercial use and sourcing training material from licensed images.
- Stable Diffusion, an open source model that kicked off a whole revolution in image generation we will cover in the next post.
- Bing Create, a partnership between OpenAI and Microsoft on the next version of “Dall-E 2”, lovingly called “Dall-E 2 Exp”.
- Midjourney v5, the latest commercial model from their research lab, perhaps the most impressive of the bunch with a very active and fast-growing community.
Even if you aren’t impressed by any of these individual images, I instead direct your attention how quickly the rate of improvement has been. All the services above have a free tier, feel free to try them out with your own prompts!
One model not listed above but worth keeping an eye on is ImageN from Google. You can see a few examples of what it’s capable of on their website. It remains to be seen if Google will eventually release a version of this publicly.
Prompt Engineering
Another reason this capability is impressive, is that the images shown above came from a prompt I didn’t spend very much time thinking about. It was just the first sentence that popped in my head. People have been able to achieve vastly superior quality by really crafting their prompt to better direct the AI.
Here’s a couple of photo-realistic AI-generated images that have been doing the rounds lately:


Do I have your attention yet? These are FAKE AI-generated images, but it takes quite a bit of scrutiny to find out. In the Pope’s image, note how his hand that is holding what seems to be a Starbucks cup appears mangled. In Trump’s case, the photo is missing a finger.
Both of these images were made by Midjourney v5, and I suspect by the time v6 rolls out, it will be increasingly hard to tell which images are fake and which are real. We’ll have to rely on the sources they come from and other ways of confirming visual evidence instead.
Here are a couple examples of beautiful artistic images that further showcase how high quality image generation can get:
 “character concept, cute baby dragon in the woods, dungeon and dragons, fantasy, medieval”, from Midjourney
“character concept, cute baby dragon in the woods, dungeon and dragons, fantasy, medieval”, from Midjourney
 “a renaissance painting of an elephant in a tuxedo”, from Bing Create
“a renaissance painting of an elephant in a tuxedo”, from Bing Create
So, what’s the takeaway? With sufficient effort put into your prompt, you can create very high quality photo-realistic as well as artistic images!
The process of writing great prompts is often referred to as “prompt engineering”. While over time we expect image generation models to produce fantastic outputs just from simple descriptions, their usage today predominantly relies on creative use of prompts to obtain the desired results.
It’s also note-worthy that prompts that work well in one model don’t necessarily translate to another. I recommend sticking with a single tool and refining your prompts there, learning through iteration. Midjourney’s interface is particularly good for this - the main way to make images with them is by joining their Discord. There you can watch other users go through the process of creating images, which is sure to inspire you. And you will learn a few tricks to make great prompts along the way!
Image-to-image
Turning text into pictures is the most common use of image generation models. However, they can also be applied to existing images. This is a very useful capability to further refine images you made through prompting, or to enhance photos or art that already exist.
There are four main ways you can use this capability.
Upscaling
This is the simplest application of image-to-image models. You can take an image that is of low resolution (say 512x512 pixels) and upscale it to a higher resolution (say 1024x1024 pixels). This isn’t just resizing the image to make it bigger, that would just result in a blurry and ugly mess.
What the model does is repaint the image at the higher resolution, adding detail and clarity along the way to make it look good at a bigger size. It can only do this by accurately predicting what detail should be added - given the context of the image. Because modern image generation models have “seen” so many images, they are able to do this very well.
I made a favicon for this site a long time ago and still only have the low resolution 64x64 version of it. It looks pretty blurry when scaled up to 256x256, let’s see how the upscaler does:


Nice! Very crisp, and it picked up on the grunge font details.
Style transfer
This process can take the style from one image and apply it to another. The classic example of this process is the “Mona Lisa” in the style of “Starry Night”:

Style transfer technology (known as neural style transfer) has actually existed for a while, and predates modern text-to-image models. These are basically “filters” that Instagram, Snapchat, and TikTok have made so popular. However, advancements in text-to-image models have made image-to-image style transfers much more versatile and flexible.
Previously available techniques required a model to be pre-trained for a specific style. Present-day style transfer can be done much more fluidly by first generating an image (e.g. by using prompting as we discussed above) in a particular style, then mixing it with an image of a subject. This is a much more flexible approach, and opens the door to mixing and matching any style with any subject. Remixing is now limited only by your imagination!
 Mona Lisa in the style of a New Yorker front page caricature, illustration
Mona Lisa in the style of a New Yorker front page caricature, illustration
Inpainting
Inpainting is the process of replacing a portion of an image with something else. This process works similarly to the text-to-image process we talked about earlier. The only additional complexity is that the generated image is aware of the image content surrounding it and tries to blend in well.
Like style transfer, inpainting as a concept and technology has existed for a while and also predates modern text-to-image models by several years. However, because of these new image generation capabilities, you are able to go far beyond the classical use-cases of inpainting, in a much more flexible and generalizable way.
Fixing defects
The simplest application of inpainting is used to restore damaged parts of images. The canonical example here is to remove scratches from scanned analog pictures. This capability has been available from even early versions of OpenCV:
 Damaged Version
Damaged Version
 Restored Version
Restored Version
Removal
Modern inpainting can do a lot more than that. Google recently launched “Magic Eraser” in Google Photos, which can remove arbitrary subjects or objects from images, which is a potent example of this capability.
Pixel 6 Magic Eraser tool at work pic.twitter.com/dyeUa76HYe
— Shevon Salmon (@its_shevi) October 25, 2021
Check out this page of real world examples of magic eraser at work - you can remove not just people, but almost every object in the frame.
Replacement
An even more powerful application is replacing subjects or objects with something else. Note how text-to-image models we used above can sometimes struggle with generating detailed human faces that look natural. Well, inpainting just the face and iterating through a few more generations with models optimized to generating good human faces can help fix that!
Let’s try this technique on the image we generated earlier of Arjuna on a horse using Stable Diffusion:
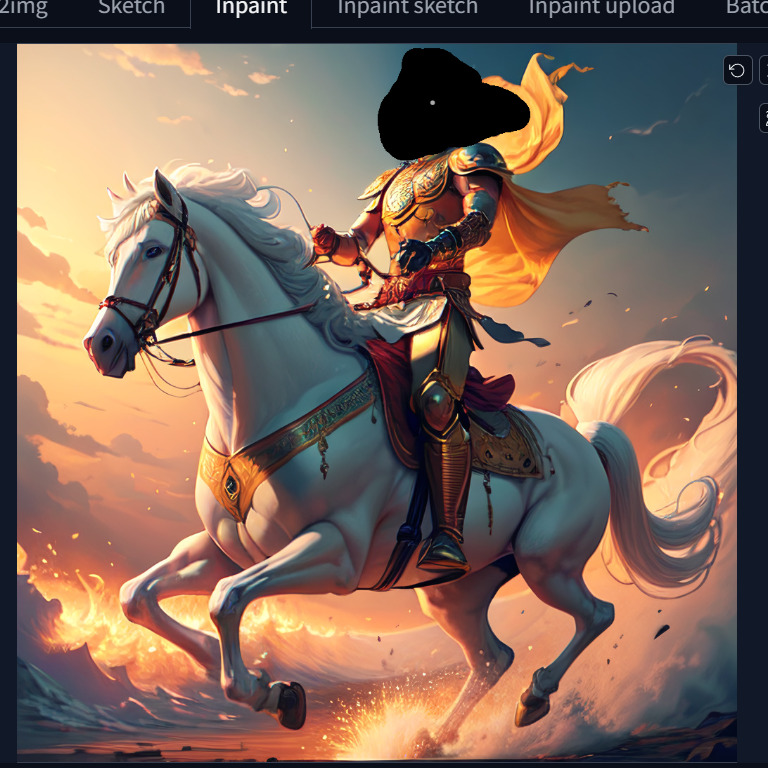 Mark portion of image to replace
Mark portion of image to replace
 Newly generated face blended in!
Newly generated face blended in!
Now we’re really getting somewhere! We can use the same inpainting techniques to fix other issues with the image, such as the hand holding the reins.
Outpainting
OpenAI was first to apply the inpainting technique in a creative way — to extend the boundaries of an existing image. Outpainting can be thought of as inpainting, but with a blank canvas extending beyond the original boundaries. This lets you dream up how an image might be extended in a way that matches the original style and blends in.
The artist August Kamp collaborated with OpenAI and used Dall-E to outpaint the classic Dutch painting “Girl with a Pearl Earring” by Johannes Vermeer:
 Original Painting by Johannes Vermeer
Original Painting by Johannes Vermeer
 Imaginative Expansion by August Kamp
Imaginative Expansion by August Kamp
You can watch the full process of outpainting in action in the original blog post from OpenAI.
Image-to-text
One interesting possibility is that of applying these image models — in reverse — to generate descriptive text of any picture.
This technique is not to be confused with Optical Character Recognition (OCR for short), which is a method to extract any text found in pictures into a digital form — for example scanning the phone number from a photo of a receipt.
Instead, I’m talking about using these models to describe an image in natural language, essentially captioning them. As an example, let’s take the following image and feed it to “clip-interrogator”, a popular python library that combines the two most-used image captioning models (CLIP from OpenAI and BLIP from Salesforce).
 Still from a Gorillaz music video
Still from a Gorillaz music video
from PIL import Image
from clip_interrogator import Config, Interrogator
image = Image.open('gorillaz.jpg').convert('RGB')
ci = Interrogator(Config(clip_model_name="ViT-L-14/openai"))
print(ci.interrogate(image))
Running this program prints:
cartoonish illustration of a man in front of a table with a tablecloth,
2d gorillaz,
winning awards,
handsome hip hop young black man,
excited facial expression,
goro and kunkle,
victorious on a hill,
dvd cover,
table in front with a cup
Cool! You can imagine feeding text similar to this as a prompt to various text-to-image models to generate creative variations. Besides the obvious use-cases around accessibility, there are many interesting applications of this technology that revolve around prompt engineering and creating your own custom image models that we will discuss in future posts.
Text-to-video
Ok, we’ve already covered a lot! But, stay with me, we have one more potential application to cover.
Generating full-fledged videos from a plain language description is a rapidly emerging field. While there are no readily available tools to do this today like there are for image generation, three key players to watch are:
- Meta AI kick-started innovation in this area and published impressive demos of their “make a video” research late in 2022.
- This was shortly followed by Google’s ImageN video generation demos about a month later, which are equally impressive.
- RunwayML seems closest to providing a usable commercial tool. Their “Gen1” product allows video editing of existing videos through text prompts, while “Gen2” promises full video generation capabilities like the Meta and Google demos showed above.
Some community members have hacked together a poor man’s version of text-to-video, by stitching together multiple generated images using a tool called ControlNet to more finely control the output. This is an advanced technique that is out of scope for this post, but we may discuss it in the future.
Ethical considerations
“With great power comes great responsibility.”
-Uncle Ben
We just walked through a lot of awesome capabilities and there is a lot to be optimistic about. Just imagine the reaction of a renaissance-era painter upon hearing that one day there will be a machine that can produce any imaginable art from just a plain language description of it!
But, as with any major technological leap, there are a myriad number of ways to misuse these tools. We’ve seen this happen with PCs, the internet, mobile phones, and social media — the potential for abuse with AI is going to be much larger because these capabilities are so much more powerful. I believe the potential for abuse with image generation models is particularly high because pictures and video tend to be much more evocative and believable.
- Impact on artists. These models gained their capabilities by learning from the vast amount of images generated and cataloged by artists and photographers who published their work on the internet. Some model creators were careful to only source licensed content (e.g. Adobe Firefly) and give artists tools to exclude their work from training sets. Others (e.g. Stable Diffusion) were a bit more fast and loose in their image acquisition strategy.
- The debate is nuanced, as human artists also learn from other works they have observed throughout their lifetime. There is an ongoing philosophical question on what is truly original work, and what is merely remixing past observations. Society must contend with how we can sustainably compensate artists, particularly for work that eventually leads to commercial outcomes for people and teams using models to generate art based on their work.
- There is the question of how disruptive this technology will be to the livelihood of artists and illustrators. These tools certainly make them all much more productive, but the fact remains that as productivity rises, industries will need fewer people to produce the same amount of work. My suggestion for both aspiring and established creatives is to start mastering these tools.
- The very top artists of the world will be in greater demand to create truly unique and creative work that the world has not seen before. This is already happening in the modern art world. Scarcity will generate value, but this value is likely to be captured by a handful of the world’s best.
- Impact on society. This technology will very likely be used to generate fake news and misinformation, as we showed with the images of Trump and the Pope above. We’ve seen this happen with “deepfakes” — fabricated images or videos portraying individuals saying things they never said, or in situations that never occurred in reality. Deepfakes were challenging and laborious to make by hand, until now. This will become a trivial process going forward, something that can be done in large quantities even by non-technical people. The “evidence of your eyes” will require much more scrutiny in this new era.
- Abuse such as blackmail or revenge porn based on fabricated images are highly likely to become more commonplace. Governments should move quickly to enact and enforce stringent laws to protect individuals from this type of misuse.
- These models have shown to reflect bias that exists in the world and their training data. There is potential for unintentionally reinforcing harmful stereotypes. Indeed, in my own experience, I’ve noticed these models tend to generate humans with fair skin, light eyes, and blonde hair by default. Generating a diverse set of images of various body types, skin tones, and hair colors requires a lot more intentional effort.
- On a larger scale, this technology will be weaponized to spread propaganda and influence politics worldwide. In the long run, society as a whole will need to adapt as a response to the inundation of fake content, as we grow to rely more on authoritative and trustworthy sources for information.
I urge you to keep these ethical considerations in mind as you wield these extremely powerful tools to create content, but also in consuming content that will increasingly be AI-generated.
Make sure to read and adhere to the licenses that you agree to when using these models, as they also reinforce the ethical considerations above. Be mindful of the impact that your creations will have on society and other individuals.
Model comparison
Ok, now that you’ve seen what the breadth of capabilities are, let’s summarize the most talked about tools available today!
| Model | Features | Price | Notes |
|---|---|---|---|
| RunwayML |
✅ Inpainting ✅ Outpainting ✅ Customization See full list of their AI magic tools. |
Free trial for the first 25 images. $12/month for 125 images/month thereafter. |
Runway's claim to fame is their easy to use video editing tools. Their AI magic tools cover a wide range of capabilities, some of which are newer and less mature. |
| Dall-E 2 |
✅ Inpainting ✅ Outpainting ❌ Customization |
Free for 15 images per month. $0.016-$0.020 per image thereafter. |
Dall-E 2 is useful for generating abstract or artistic images. It is less competitive at photorealism. |
| Adobe Firefly |
❌ Inpainting ❌ Outpainting ❌ Customization |
Free during the beta. | Adobe's focus is on generating content that is safe to use commercially. However, during the beta, no commercial use is allowed, and additional features such as inpainting and customization are still in the works. |
| Dall-E 2 Exp (Bing Create) |
❌ Inpainting ❌ Outpainting ❌ Customization |
First 25 images are created fast. Subsequent images are still free, but slower to generate. |
Bing hosts an improved version of Dall-E 2 on their website. It produces higher quality images than stock Dall-E 2 but cannot be customized, and does not support inpainting. |
| Stable Diffusion |
✅ Inpainting ✅ Outpainting ✅ Customization |
Free to run on your own computer. Cloud versions offered by multiple providers cost in the range of $0.02-$0.06 per image. |
Stable diffusion is an open image generation model that can be run locally on your computer with no restrictions and infinite usage. Stability AI also offers a paid hosted version that runs in the cloud and is more user-friendly for non-technical audiences. |
| Midjourney |
❌ Inpainting ❌ Outpainting ⚠️ Customization* * You can customize to a limited extent by uploading your own image as part of the prompt to do style transfers or redraws. Midjourney also launched /describe which can caption an image (image-to-text).
|
Free trial discontinued due to abuse. $10/month for ~200 images (varies by quality and operation). |
Midjourney has the most unique and curated art style of all these models.
They also boast a very active community and unique user interface through use of Discord. |
My recommendations:
- If you are just getting started in the world of AI image generation, start with the Bing Create tool for your first few images. It is free and easy to use, although it won’t produce the highest quality images and has no customization options.
- If you want to increase the quality of your images with minimal effort, I recommend signing up for Midjourney. They have a very active community, and their models produce the best-looking images with minimal tweaking to prompts!
- If you are fully invested in this space and don’t mind committing time to installing software and tweaking your prompts, I highly recommend Stable Diffusion. You can get the highest quality outputs with sufficient prompt engineering, and the customization options are unparalleled.
I’ve been personally spending the most time with Stable Diffusion (and a little on Midjourney) — my next post will cover some ways in which you can fine-tune your own models with Stable diffusion to include your own styles and subjects!
I hope you enjoyed this introduction, and that you’ll unleash your creativity with these newfound superpowers. Please do so responsibly ❤️